Onsdag 19 Oct 2022
2022-10-19 23:30:26
Lade till lite grafer för rodd
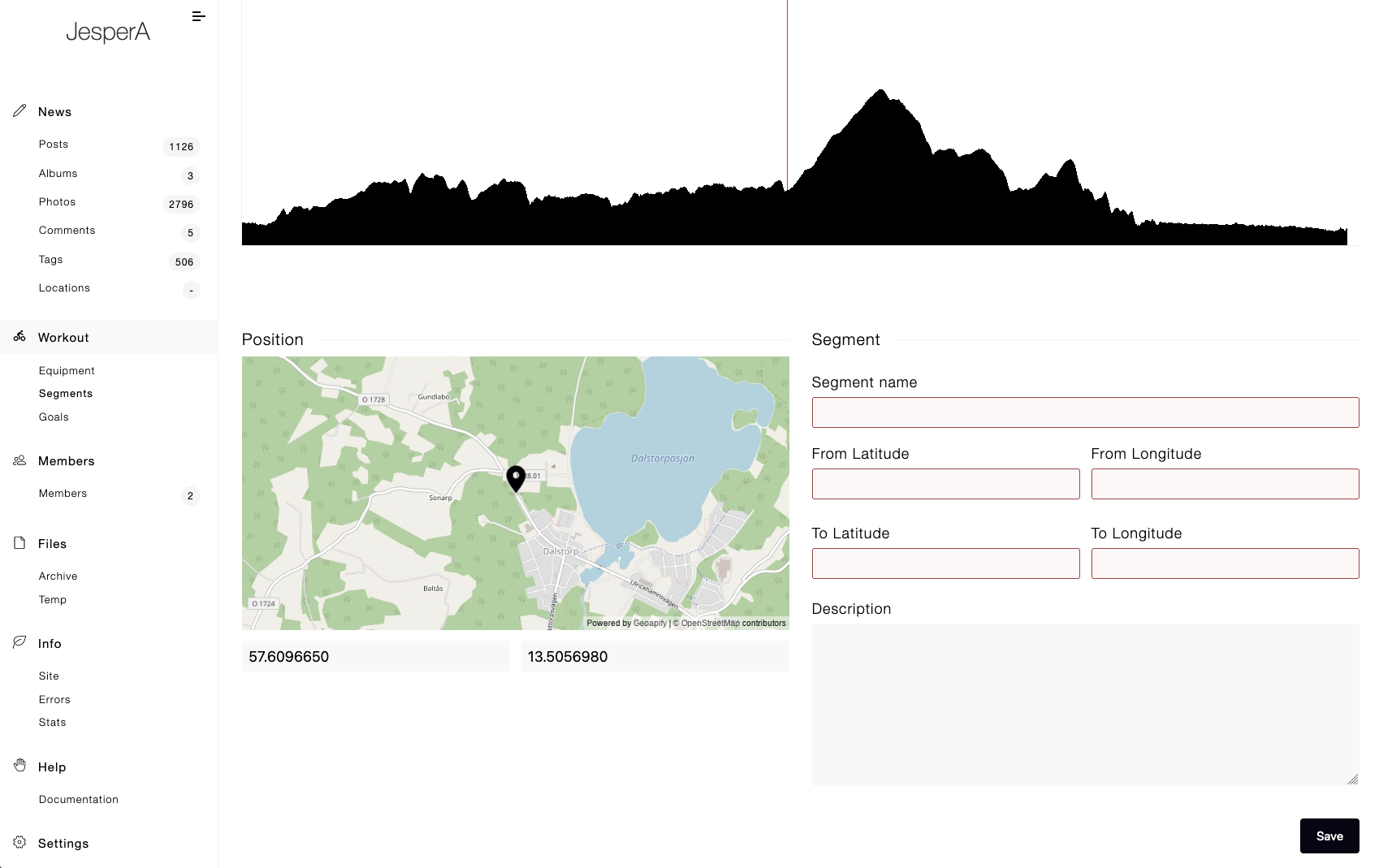
I några år nu så har jag haft ett höjd-"histogram" under kartan i inläggen för cyklingen, jag har aldrig varit nöjd med utseendet på den, vet inte riktigt varför men japp, egentligen var det tänkt att jag skulle lägga till fler histogram; tex puls, tempo, i framtiden watt om jag skaffar kraftmätare osv osv, men eftersom jag inte gillade utseendet så har det inte blivit av att jag lagt till det, ville komma på en bättre design först
Tänkte att jag experimenterar när det gäller utseendet i rodden sålänge, det har ju varit lite för lite info under rodd ändå, har ju bara haft sammanfattningen hittills; distans, tid, tempo, watt, puls, kalorier & nu har jag alltså lagt till lite histogram under + zon-info
Jag gillar fortfarande inte designen 🤷♂️
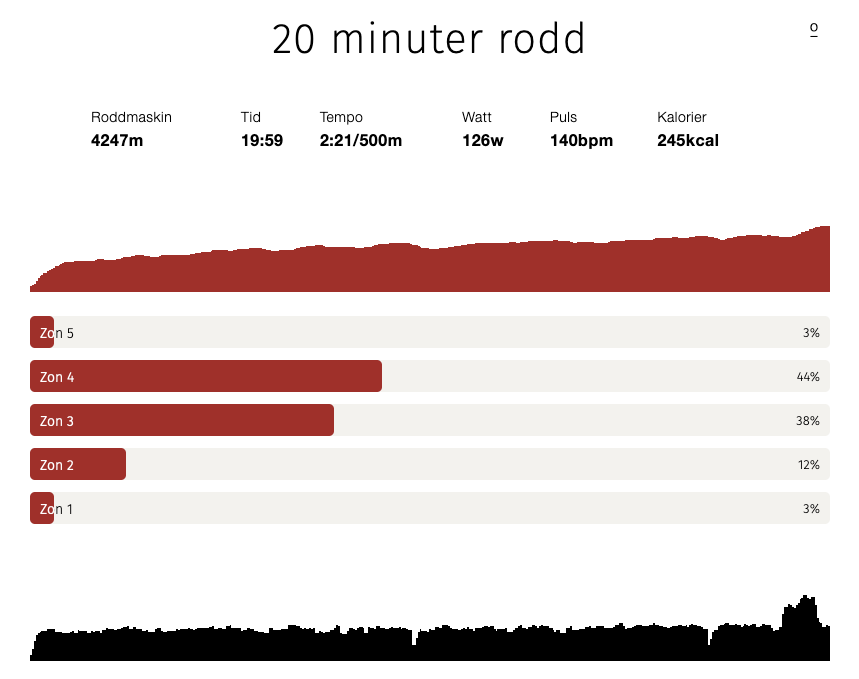 Det är fult, tar för mycket plats osv osv, måste komma på någon bättre design för egentligen skall det tillkomma fler histogram både för rodd & för cykling, kommer bli ett jumla scrollande, kanske inte gör något, kan ju "toggla" fram datan i värsta fall också men då blir det ju ett klick extra om man vill se infon. Så, hur skall jag kompakta det utan att det ser trångt & kladdigt ut? Jag vill ha en minimalistisk design men ändå inte för abstrakt
Dessutom är det ett extra problem med histograferna för rodd: graferna blir taggiga, det finns helt enkelt inte tillräckligt med datapunkter, när det gäller cykling så finns det 1 datapunkt per sekund & dom flesta av mina cykelturer är +2 timmar så då har jag ju minst 7'200 datapunkter att använda, fast det är för många så jag sållar bort dom flesta ändå, roddmaskinen däremot mäter bara var 3-5s (fast graferna i "ErgData" är mycket mjukare & "högupplösta" så det verkar som roddmaskinen faktiskt mäter oftare men att den sen inte sparar all data till .csv filen) + att jag tränar bara 20-30min så japp, det finns inte tillräckligt med datapunkter att göra en "mjuk" graf av, kanske får gå över till canvas eller svg 🤷♂️
Det är fult, tar för mycket plats osv osv, måste komma på någon bättre design för egentligen skall det tillkomma fler histogram både för rodd & för cykling, kommer bli ett jumla scrollande, kanske inte gör något, kan ju "toggla" fram datan i värsta fall också men då blir det ju ett klick extra om man vill se infon. Så, hur skall jag kompakta det utan att det ser trångt & kladdigt ut? Jag vill ha en minimalistisk design men ändå inte för abstrakt
Dessutom är det ett extra problem med histograferna för rodd: graferna blir taggiga, det finns helt enkelt inte tillräckligt med datapunkter, när det gäller cykling så finns det 1 datapunkt per sekund & dom flesta av mina cykelturer är +2 timmar så då har jag ju minst 7'200 datapunkter att använda, fast det är för många så jag sållar bort dom flesta ändå, roddmaskinen däremot mäter bara var 3-5s (fast graferna i "ErgData" är mycket mjukare & "högupplösta" så det verkar som roddmaskinen faktiskt mäter oftare men att den sen inte sparar all data till .csv filen) + att jag tränar bara 20-30min så japp, det finns inte tillräckligt med datapunkter att göra en "mjuk" graf av, kanske får gå över till canvas eller svg 🤷♂️
Det är fult, tar för mycket plats osv osv, måste komma på någon bättre design för egentligen skall det tillkomma fler histogram både för rodd & för cykling, kommer bli ett jumla scrollande, kanske inte gör något, kan ju "toggla" fram datan i värsta fall också men då blir det ju ett klick extra om man vill se infon. Så, hur skall jag kompakta det utan att det ser trångt & kladdigt ut? Jag vill ha en minimalistisk design men ändå inte för abstrakt
Dessutom är det ett extra problem med histograferna för rodd: graferna blir taggiga, det finns helt enkelt inte tillräckligt med datapunkter, när det gäller cykling så finns det 1 datapunkt per sekund & dom flesta av mina cykelturer är +2 timmar så då har jag ju minst 7'200 datapunkter att använda, fast det är för många så jag sållar bort dom flesta ändå, roddmaskinen däremot mäter bara var 3-5s (fast graferna i "ErgData" är mycket mjukare & "högupplösta" så det verkar som roddmaskinen faktiskt mäter oftare men att den sen inte sparar all data till .csv filen) + att jag tränar bara 20-30min så japp, det finns inte tillräckligt med datapunkter att göra en "mjuk" graf av, kanske får gå över till canvas eller svg 🤷♂️